from docling.document_converter
import DocumentConverter
converter = DocumentConverter()
result = converter.convert(pdf)
md = result.document
.export_to_markdown()
# ppc64le & ppc64 native
$ pip install docling
$ docling my-report.pdf
--to markdown --to json
# Output: structured data ✓
Live
—
ppc64le & ppc64 (AIX)
🦆
Docling
Docling
on Power
Document extraction and RAG preparation for IBM Power infrastructure.
PDF, DOCX, PPTX → structured chunks. Native on ppc64le & ppc64.
How it works
Documents in. Structured chunks out.
Docling parses page layouts, extracts tables, detects formulas, and outputs clean Markdown, JSON, or HTML — ready for your RAG pipeline. Retrieval and search are powered by LLMs via API.
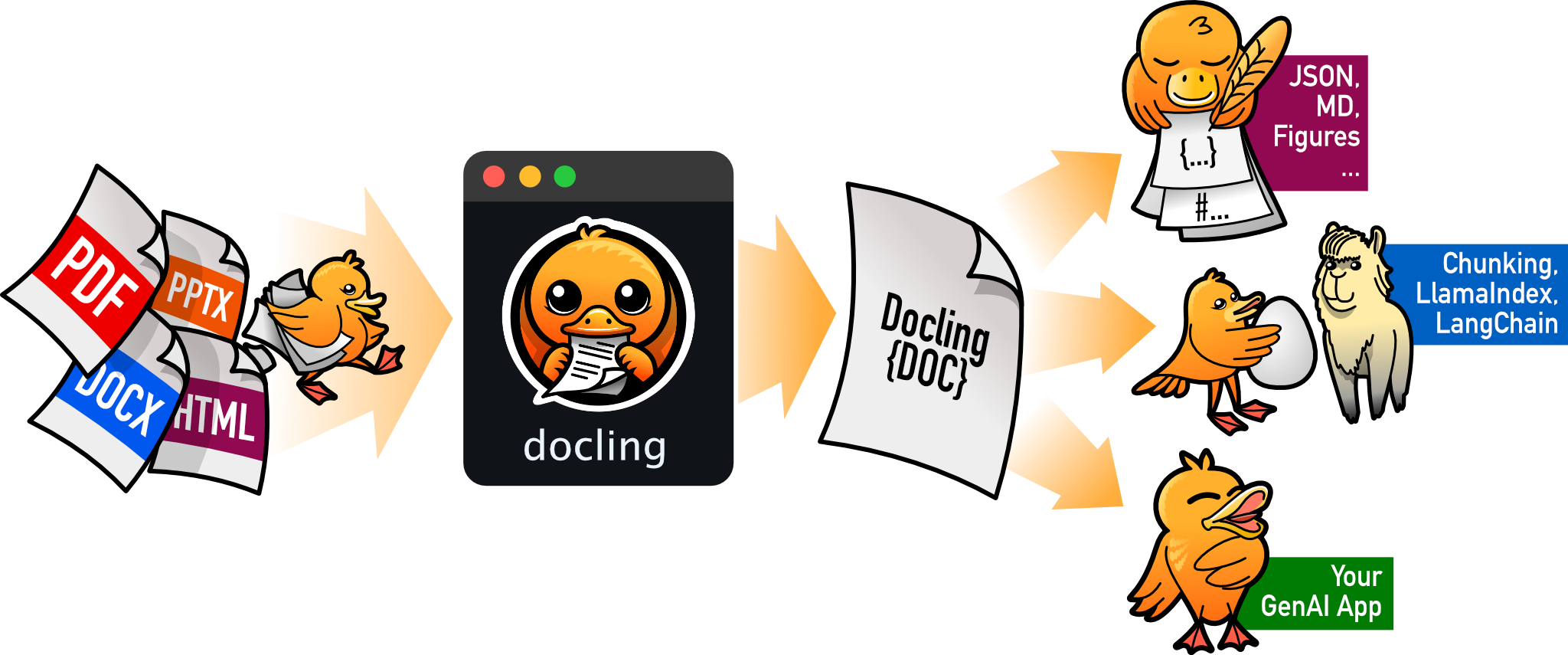
Docling processing pipeline — from raw documents to structured, RAG-ready chunks.
Input & Output
Every format. One pipeline.
🦆
Docling
Scroll to explore the pipeline
Feed Docling any document format and get structured, machine-readable output.
Parse complex PDF layouts — tables, headers, reading order, formulas, and more.
Convert Office files — Word documents and PowerPoint presentations.
Process spreadsheets and web pages into structured data.
Handle images with OCR for text extraction from scanned documents.
Export to JSON, Markdown, or HTML — ready for RAG chunking.
Use plain text for simple extraction and downstream processing.
Structured chunks
On Power
Platform support
Native on ppc64le & ppc64 (AIX)
LibrePower's port of Docling brings document extraction and RAG preparation to IBM Power Systems — Linux (ppc64le) and AIX (ppc64). No x86 emulation. No GPU required.
quickstart.py
# Install on ppc64le or ppc64 (AIX) # pip install docling from docling.document_converter import DocumentConverter source = "quarterly-report.pdf" converter = DocumentConverter() result = converter.convert(source) # Export to Markdown for RAG md = result.document.export_to_markdown() # Or export to JSON for processing json_data = result.document.export_to_dict()
Get started
Bring document extraction to your Power infrastructure
Deploy Docling on IBM Power today. Extract and chunk your documents for RAG — on-premises processing, LLM-powered search via API.